카테고리 없음
MetaFormer is Actually What You Need for Vision 논문리뷰
- -

기존 Transformer에서는 Token Mixer 영역을 Attention으로 해서 처리했고, 많은 논문들에서는 Attention을 개선시키는 시도를 했다. 최근에는 attetnion을 MLP로 바꾼 모델도 성능이 좋았고, 이 논문에서는 단순하게 공간 Pooling을 통해 이를 개선시켰다.
그래서 이 논문에서는 Transformer의 기존 Attention 영역을 Token Mixer라고 추상화하는 형태인 Metaformer 아키텍처를 제안한다. Pooling을 기반으로 한 PoolFormer는 향후 MetaFormer 아키텍처 설계를 위한 좋은 baseline으로 사용할 수 있다고 제안하고 있다.
- Transformer 기반 모델의 성공은 Attention 때문이 아니라 MetaFormer 아키텍처 때문이라고 주장하고 있다.

진짜 그냥 Average Pooling을 쓰고 있다.
3. Method
3.1. MetaFormer

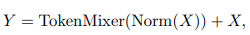

- 식2 : Norm은 Layer Normalization이나 Batch Normalization이 될 수 있다. TokenMixer는 token 정보를 mixing하는데 사용하는 모듈로 최근에는 다양한 Attention 기반 모델 또는 MLP 기반의 모델로 구현되었다.
- 식3 : 2 layered MLP와 non-linear activation으로 구성 (일반적 ViT 구조와 동일한데 그냥 추상화한다고 공식처럼 풀어놓은 것 같습니다.)
3.2. PoolFormer




PoolFormer 파트에서는 Patch Embedding 관련해서 patch size, stride 변경해서 적용한 몇 가지 실험결과를 소개하고 있다.
표2의 결과를 보면, Attention과 Spatial MLP 기반의 Transformer에서는 CNN에 미치지 못한 성능이 나오지만, PoolFormer에서는 CNN을 능가하고 있다. 그리고 Attention, MLP 기반보다 파라미터 수도 적은 모델이라는 걸 볼 수 있다. 이는 Object Detection, Instance Segmentation, Semantic Segmentation에서는 파라미터도 상대적으로 적고 더 좋은 성능이 나오는 걸 보여주고 있다.
이 논문에서는 Transformer의 기본 아키텍처 자체에 좀 더 집중하여 설명하고 있다. 단순히 Attention이나 spatial MLP를 적용해서 잘 됐던 것이 아니라 아키텍처의 영향이 크다고 판단하여 단순 Pooling만 적용했음에도 좋은 결과가 나왔음을 보여주고 있다.
기존의 Transformer 기반으로 성능 향상이 되었던 다양한 Task의 모델들(Pose Estimation, Human Mesh Reconstruction 등)도 PoolFormer를 통해 개선이 될 수 있을 것 같고, MetaFormer라는 아키텍처에서 다양한 실험들을 해서 더 좋은 모델들도 나올 수 있는 여지를 남긴 논문인 것 같다.
참고자료
https://arxiv.org/pdf/2111.11418.pdf
https://github.com/sail-sg/poolformer
GitHub - sail-sg/poolformer: PoolFormer: MetaFormer is Actually What You Need for Vision
PoolFormer: MetaFormer is Actually What You Need for Vision - GitHub - sail-sg/poolformer: PoolFormer: MetaFormer is Actually What You Need for Vision
github.com
Contents
소중한 공감 감사합니다