카테고리 없음
A TRANSFORMER-BASED SIAMESE NETWORK FOR CHANGE DETECTION 논문리뷰
- -

두 개의 사진의 차이점을 비교하는 Change Detection 분야의 논문인데 Transformer 기반으로 만들어졌습니다.
Siamese 네트워크 구조를 참고해서 계층적 transformer encoder와 여러 스케일의 feature 차이를 계산하는 4개의 feature 차이 모듈 및 경량 MLP Decoder를 사용해서 multi-level feature 차이를 융합하고 CD(Change Detection) mask를 예측한다.
1. Hierarchical Transformer Encoder
그림1에서 볼 수 있듯이 input bi-temportal image(찍은 시점이 다르고 카메라가 같은 두 이미지)가 주어졌을 때, 고해상도의 coarse feature와 저해상도의 fine-grained feature를 생성한다. 두개의 transformer encoder layer들은 weight를 공유하고, 차원이 축소될 때마다 Difference module을 통해 difference map을 계속 얻는다.
- Transformer Block : 기존 transformer의 attention 방식을 사용하면, 계산 복잡도가 크기 때문에 고해상도 이미지들에 적합하지 않다. 그래서 계산 복잡도를 줄이기 위해 Sequence Reduction 방식을 사용한다. (Pyramid Vision Transformer, https://bo971011-record.tistory.com/23?category=981466 참조)
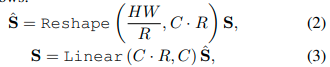

- Downsampling Block : i번째 transformer layer에서 input patch F_i가 주어졌을 때, downsampling layer는 F_i를 절반으로 줄여서 F_(i+1)를 얻는다. (H/2 x W/2 x C -> H/4 x W/4 x C) 그리고 다음 transformer layer input으로 사용한다.
- Difference Module : Conv2D, ReLU, BatchNorm2D로 Difference Module을 구성한다. 아래의 식5에서 F_pre_i, F_post_i는 pre-change(전), post-change(후) 이미지들의 i번째 계층 레이어의 feature map을 의미한다.
F_pre, F_post의 절대적 차이를 계산하는 대신, 제안된 difference module은 최적의 거리 metric을 학습할 때마다 배움으로써, 더 나은 CD performance 결과를 나타내게 된다.

2. MLP Decoder
difference map을 예측하기 위해 multi-level difference map을 집계하는 MLP layer로 구성된 간단한 디코더를 사용한다.
- MLP & Upsampling : 먼저 MLP layer를 통해 multi-scale feature difference map을 처리하여 채널 차원을 통합한 다음 H/4 x W/4 크기로 업샘플링한다.

- Concatenation & Fusion : 업샘플링된 feature difference map은 MLP layer를 통해 연결(concat) 및 융합된다. (식8)
- Upsampling & Classification : S=4, K=3인 2D transposed convolution layer를 이용해서 융합된 feature map F를 HxW 크기로 업샘플링한다. 마지막으로, 업샘플링된 융합된 feature map은 다른 MLP layer를 통해 처리되어 HxWxN_cls의 change mask를 예측하는 데 사용된다. 여기서 N_cls는 클래스 수로 2이다. (변경되었는지 아닌지).
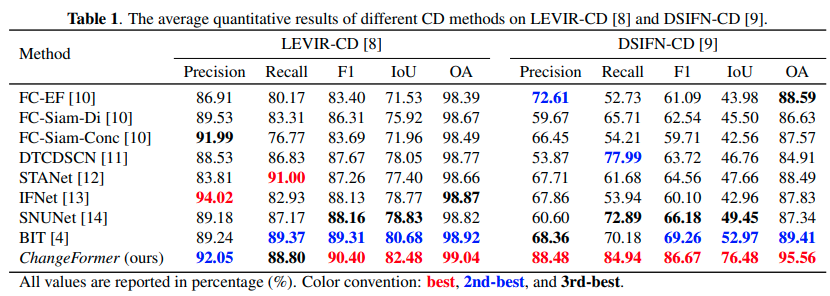
결과
참고자료
Contents
소중한 공감 감사합니다