딥러닝, 머신러닝/논문리뷰
Image Retrieval(Metric Learning) 기본 - LEARNING SUPER-FEATURES FOR IMAGE RETRIEVAL
- -
Image Retrieval(Metric Learning)에 관해 공부하던 중, 인상깊게 본 논문이 있어 소개드립니다.
올해(2022년) 네이버랩스 유럽에서 발표된 논문입니다.
먼저 Image Retrieval(metric learning)은 쇼핑사이트(네이버, 쿠팡 등)에서 동일한 상품을 하나의 카탈로그로 묶어서 고객에게 보여주는 데도 사용될 수 있는 방법입니다.
그 절차를 간단하게 정리하자면, 이미지에서 CNN과 같은 네트워크를 거쳐서 최종 feature를 뽑고(softmax layer 이전 상태), 그 feature들을 모아서 KNN과 같은 방식을 사용해서 유사 제품을 찾는 형태라고 할 수 있습니다.
https://github.com/KevinMusgrave/pytorch-metric-learning
위의 깃허브 코드가 이해하는 데 많이 도움이 됐습니다. colab 소스도 참고할 만 합니다.
논문 설명 전 이 논문에서 사용되는 몇가지 용어를 정리하겠습니다.
- local feature : CNN에서 softmax 전, 가장 끝단의 feature, 보통 FC layer의 output일 걸로 추정됩니다.
- super feature : 이 논문에서 제시하는 것으로, 모델의 가장 끝단에서 feature를 가져오는 local feature에 비해, 모델의 중간 수준에서 feature를 가져와서 image retrieval(이미지 검색)을 하는 용도로 사용합니다.
이 논문에서는 다음과 같은 점을 지적하고 있습니다.
1. image retrieval에서 사용하는 기존의 feature(local feature)는 신경망에서 local map activation의 결과값, 즉 레이어 끝단의 값으로 사용되는 것이라서 중복이 많은 문제가 발생한다.
2. 학습/테스트 간의 불일치 문제 : 학습 시 local feature의 집계(aggregation)에만 작용하는 global loss를 사용하는데, 테스트는 local feature의 일치를 기반으로 해서 기준점이 달라지는 불일치 문제가 발생한다. 기존 방식(local feature - global loss)에서는 부분적으로 일치하는 feature에 더 집중하기 때문에 그렇다고 합니다.
이러한 문제를 해결하기 위해, 주변 정보도 활용할 수 있는 attention 모듈을 image retrieval 작업에 맞게 조정해서 사용하고, 그 모델 이름을 Local feature Integration Transformer(LIT)로 칭하고 있습니다.

위의 그림을 보면, attention 모듈(LIT)에서 생성된 5개의 super feature를 확인할 수 있습니다.
1, 2행은 같은 랜드마크의 다른 시점 이미지이고, 3행은 성당 같은데 다른 장소 이미지입니다.
위의 3개의 이미지에 대해 동일한 이미지라고 생각되는 5가지 특징이, 오른쪽 5개의 super feature 이미지로 나왔다고 볼 수 있습니다.
특정 영역에만 집중된 local feature와는 다르게 다양한 영역에서 곡선, 삼각형 등 여러 특징들을 뽑아내고 있습니다.
기존 local feature는 구글 검색 결과를 참고하시면 좋을 것 같습니다.
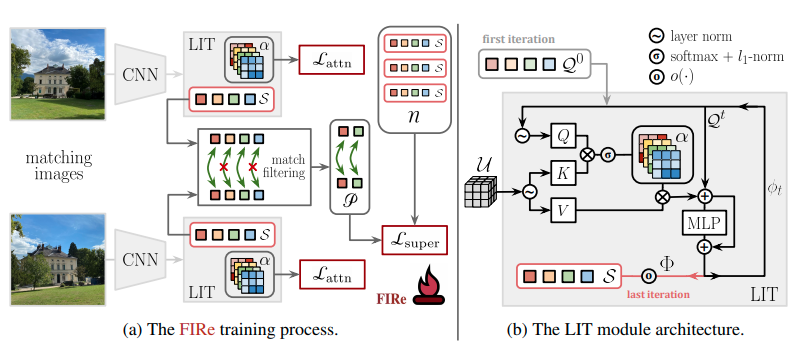
모델 구조를 보면, 찾을 이미지, 비교할 이미지를 CNN 인코더에 넣어서 LIT를 통해 매칭되는 super feature를 찾고, 일치여부를 match filtering을 통해 판단하고 있습니다.
("이 방식이 성능은 올려줄 지 모르겠지만, 이런 구조로 가면, 네이버쇼핑이나 쿠팡, 아마존 등 실제 비교할 데이터가 매우 많은 상황에서는 시간 문제 때문에 쓰기 어렵지 않을까 싶네요.")

간단하게 정리하면, 쿼리 이미지(새로운 이미지, 검색대상)와 기존 이미지의 super feature의 쌍을 비교해서 T값(임계치, threshold) 이상이면 일치하는 걸로 보는 것 같습니다. 이 논문에서는 T값을 0.9로 설정했다고 합니다.
유사도 기준은 코사인 유사도를 사용했습니다.

성능은 다른 SOTA 대비 더 좋아졌다고 합니다.
참고자료
https://openreview.net/pdf?id=wogsFPHwftY
'딥러닝, 머신러닝 > 논문리뷰' 카테고리의 다른 글
Contents
소중한 공감 감사합니다