기타
NVIDIA Triton Server 사용기 (모델 경량화, 서버 API 속도개선)
- -
안녕하세요
이번에 회사에서 모델 API 서버를 개발하면서 NVIDIA Triton server(트리톤 서버)을 적용해봤는데요.
확실히 2배 이상 속도 개선도 되고, django를 쓰던 방식보다는 훨씬 안정적으로 운영할 수 있었습니다.
무엇보다 경량화 때문에 GPU 점유율도 낮아져서 여러 모델을 다 올릴 수 있어서 좋더라구요.
다만 혼자 찾아가며 하려니, 정확히 필요한 게 하나로 정리된 글이 없어서, 삽질이 굉장히 많았습니다.
그래서 적용하는 방법을 이 글에 모두 정리하기 위해 글을 씁니다.
이 글에서 다룰 내용은 아래와 같습니다.
1. Nvidia Triton Server를 사용해야 되는 이유
2. 내 모델을 Triton Server에 넣는 방법
3. 실제 사용 후기
1. Nvidia Triton Server를 사용해야 되는 이유
1) 속도 (경량화)
GPU 너무 부족한데?
"이런 경험, 한번쯤 있으시죠?"
특히나 요즘 모델들은 Transformer가 대부분 적용되어 있는데, 모델 자체가 무거운 경우가 많습니다.
django 등 일반적으로 쓰는 API 프레임워크로 Pytorch 그대로 올려서 쓰면 어떻게 될까요?

GPU 메모리 이렇게 될겁니다.
실질적으로 회사에서 서비스 하나 한다고 모델 1개당 좋은 서버 하나씩 마련하는 게 비용도 만만치 않죠.
그럼 경량화 하면 되지 않냐구요? Pruning, TensorRT 등 경량화 도구들을 찾다 환경 잡고, 배우는 데만 한참의 시간이 들어가고 포기하게 됩니다..
반면에 Triton server를 쓰게 되면, 간단한 방법으로 경량화를 진행해도 최소 2배 이상 속도를 줄이고, GPU 메모리도 줄여서 여러 모델도 로딩이 가능합니다. 그냥 torch 프레임워크 설치한 것만으로도 쓸 수 있습니다. (방법은 아래에 있습니다!)
benchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=0, half=False, test=False
Checking setup...
YOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
Setup complete ✅ (8 CPUs, 51.0 GB RAM, 46.7/166.8 GB disk)
Benchmarks complete (458.07s)
Format mAP@0.5:0.95 Inference time (ms)
0 PyTorch 0.4623 10.19
1 TorchScript 0.4623 6.85
2 ONNX 0.4623 14.63
3 OpenVINO NaN NaN
4 TensorRT 0.4617 1.89
5 CoreML NaN NaN
6 TensorFlow SavedModel 0.4623 21.28
7 TensorFlow GraphDef 0.4623 21.22
8 TensorFlow Lite NaN NaN
9 TensorFlow Edge TPU NaN NaN
10 TensorFlow.js NaN NaN
yolov5 github에서 제시한 Colab V100 GPU 추론속도 비교 결과입니다.
정확도를 거의 잃지 않으면서, pytorch보다, torchscript가 약 40% 빨라졌고, tensorRT는 80% 가량 빨라졌네요
실제로 돌려봤을 때는 onnx의 경우도 속도가 0.01~0.02초 가량 나왔습니다.
(yolov5-rt-stack 기준, 아래 참고자료 소스에 있어요)
2) 쉽다
2-1) TensorRT처럼 환경세팅 다 해야 되는 거 아니에요? 아닙니다.
그냥 쿠다 버전에 맞는 docker 받아서 돌리면 끝납니다.
물론 tensorRT도 docker가 있지만, 이런저런 이유로 자꾸 안되는 경우가 생기더라구요.
2-2) 관리의 용이성
트리톤 서버(Triton Server)를 써보니까 너무 좋은게, 모델을 onnx나 torchscript로 변환한 뒤,
변환된 모델 파일(.pt, .onnx)과 config 파일 정보(input, output shape 정보)만 간단하게 작성하면,
모델 소스를 API 서버 단에 넣을 필요도 없으니까 관리하기도 너무 편하더라구요.
오케이 그럼, Triton server 왜 써야 되는지는 알겠어
그럼 이거 어떻게 쓰는데?
2. 내 모델을 Triton Server에 넣는 방법
이제 알려드리겠습니다.
1) 내 환경에 맞는 도커 이미지 받기
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags
Triton Inference Server | NVIDIA NGC
Triton Inference Server is an open source software that lets teams deploy trained AI models from any framework, from local or cloud storage and on any GPU- or CPU-based infrastructure in the cloud, data center, or embedded devices.
catalog.ngc.nvidia.com
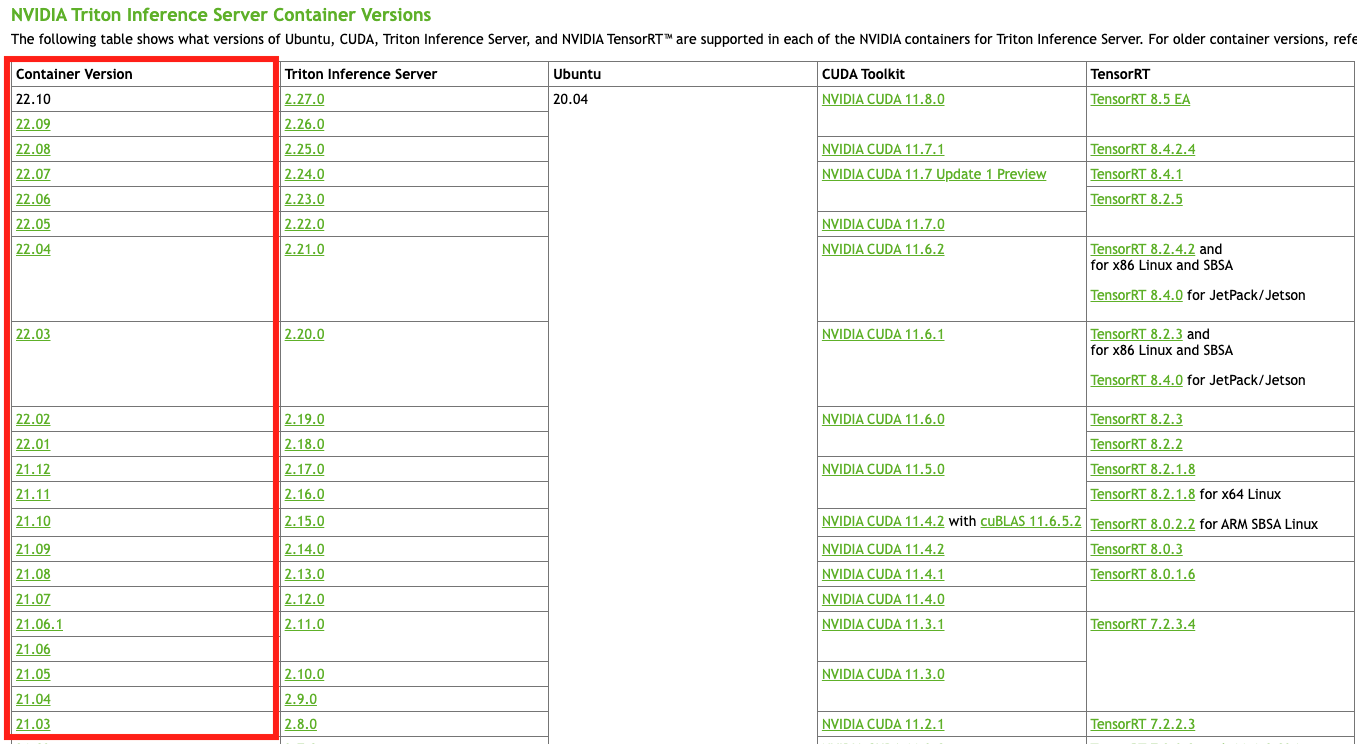
1. 위 링크에 들어가서, 내가 세팅할 PC(또는 서버) 환경에 맞는 Triton server docker 이미지의 버전(왼쪽 Container version)을 확인합니다.
2. 해당하는 docker 이미지를 받습니다.
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags
정확한 버전(Tag)은 위 링크를 보고, 아래처럼 pull 받으시면 됩니다.
docker pull nvcr.io/nvidia/tritonserver:21.03-py3
2) 내 모델을 변환하기
Triton은 아래 5개 프레임워크를 지원하고 있습니다.
Tensorflow, PyTorch, TensorRT, ONNX and OpenVINO
2-1. PyTorch
Pytorch의 경우는 torchscript로 변환된 모델을 지원하고 있고, 변환하는 코드는 아래를 참고하시면 됩니다.
상황에 따라 script가 안될 경우, trace로 해야 되는 경우가 있어요.
(모델 구조, forward 관련 코드 차이 등으로 인해)
일단 해보고 되는 방식을 사용하시면 될 것 같습니다.
먼저 추론용이니까 torch 모델을 eval()로 세팅해주신 후, 아래 2개 중 1개로 하시면 됩니다.
model = model.eval()
model = model.to(device)
trace 방식 : 모델의 input data shape에 맞춰서 dummy input을 만들고 저장해줍니다.
model_input = torch.rand(1, 64, 64)
traced = torch.jit.trace(torch_model, (model_input,))
traced.save(‘model.pt')
script 방식
traced = torch.jit.script(torch_model)
traced.save(‘model.pt')
config 파일 만들기
config 파일은 모델의 input, output shape에 맞추고, platform은 지금은 torch니까 "pytorch_libtorch"로 적어서 만들어줍니다.
(config.pbtxt)
name: "mnist_cnn"
platform: "pytorch_libtorch"
max_batch_size: 100
input [
{
name: "input__0"
data_type: TYPE_FP32
dims: [ 1, 28, 28 ]
}
]
output [
{
name: "output__0"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
2-2. ONNX
PyTorch 모델을 ONNX로 바꾸는 방법도 괜찮습니다!
(사용한 레이어, torch 버전에 따라 호환이 안되는 레이어가 있을 수도 있어요)
전부 설명하기엔 페이지가 너무 길어질 것 같아, 중요한 부분만 설명하겠습니다.
전체 코드는 아래 참고자료(yolov5-rt-stack)를 참고해주세요.
onnx 변환도 torch에서 모듈로 제공해서 편하게 할 수 있습니다.
torch.onnx.export로 하고 input, output의 name, shape을 받아 세팅하면 됩니다.
다만, onnx로 export해서 사용했을 때의 단점이 있습니다.
고정된 batch size 사용 문제
- torchscript의 경우, max_batch_size만 config에 명시해두면, 실제 추론 시 batch size 1로 보내든, 8, 16으로 보내든 돌아가는데, onnx의 경우 export할 때 딱 정한대로만 되는 문제가 있었습니다.
@requires_module("onnxsim")
@torch.no_grad()
def to_onnx(self, onnx_path: str, simplify: bool, **kwargs):
"""
Saves the model in ONNX format.
Args:
onnx_path (string): The path to the ONNX graph to be exported.
**kwargs: Will be passed to torch.onnx.export function.
"""
with BytesIO() as f:
torch.onnx.export(
self.model,
self.input_sample,
f,
do_constant_folding=True,
opset_version=self._opset_version,
input_names=self.input_names,
output_names=self.output_names,
dynamic_axes=self.dynamic_axes,
**kwargs,
)
f.seek(0)
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
if simplify:
try:
onnx_model, check = onnxsim.simplify(onnx_model)
assert check, "assert check failed, save origin onnx"
except Exception as e:
logger.info(f"Simplifier failure: {e}")
onnx.save(onnx_model, onnx_path)
3. 실제 사용 후기
실제 개발하면서 아래 Curt-Park님의 github가 많은 도움이 됐습니다!
("처음 하시는 분들은 참고하셔도 좋을 것 같아요")
TensorRT는 Pytorch의 TensorRT github 보고도 해봤는데, 변환이 안되는 경우가 많았고, 서버 환경에 맞추기도 쉽지 않아서 우선은 torchscript 기반으로 진행했습니다.
+ CUDA 10.2를 계속 쓰고 있었는데, 10.2에 맞는 docker에서는 그 때의 torch 버전이 낮아서 그런지 모르겠는데, 에러 때문에 triton server에서 모델 로딩이 안되는 경우가 자꾸 발생해서, CUDA 11.3으로 업데이트를 했습니다.
CUDA 버전 업그레이드가 필요한 경우, 아래 참고자료의 블로그 참고하시면 좀 더 편하게 할 수 있습니다.
Triton에서 지원하는 또 다른 환경인 OpenVINO는 CPU 기반이라, 가볍게 돌릴 만한 서비스의 경우 사용하셔도 좋을 것 같습니다.
참고자료
https://github.com/Curt-Park/triton-inference-server-practice
GitHub - Curt-Park/triton-inference-server-practice: Archives for Triton Inference Server Practices
Archives for Triton Inference Server Practices. Contribute to Curt-Park/triton-inference-server-practice development by creating an account on GitHub.
github.com
https://github.com/zhiqwang/yolov5-rt-stack/blob/main/yolort/runtime/ort_helper.py
GitHub - zhiqwang/yolov5-rt-stack: yolort is a runtime stack for yolov5 on specialized accelerators such as tensorrt, libtorch,
yolort is a runtime stack for yolov5 on specialized accelerators such as tensorrt, libtorch, onnxruntime, tvm and ncnn. - GitHub - zhiqwang/yolov5-rt-stack: yolort is a runtime stack for yolov5 on ...
github.com
https://github.com/pytorch/TensorRT
GitHub - pytorch/TensorRT: PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT
PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT - GitHub - pytorch/TensorRT: PyTorch/TorchScript/FX compiler for NVIDIA GPUs using TensorRT
github.com
https://evols-atirev.tistory.com/43
Ubuntu에 여러 버전의 CUDA 설치하기
여러 종류의 딥러닝 framework를 쓰다보면 여러 버젼의 CUDA가 필요하곤 합니다... 그래서 제가 겪은 경험에 의해 여러 CUDA를 설치하는 법을 공유합니다. 우선 nvidia 사이트에서 cuda 설치파일을 다운
evols-atirev.tistory.com
https://github.com/ultralytics/yolov5/issues/251
TFLite, ONNX, CoreML, TensorRT Export · Issue #251 · ultralytics/yolov5
📚 This guide explains how to export a trained YOLOv5 🚀 model from PyTorch to ONNX and TorchScript formats. UPDATED 20 October 2022. Before You Start Clone repo and install requirements.txt in a Pyt...
github.com
'기타' 카테고리의 다른 글
| django 80 port로 띄우기(caddy) (0) | 2023.02.12 |
|---|---|
| Postgresql Timezone 영구 변경하기 (0) | 2023.02.12 |
| Git 명령어 모음 (0) | 2022.11.07 |
| AI 트렌드 보는 사이트 (2) | 2022.08.03 |
| python smpl (0) | 2022.06.23 |
Contents
소중한 공감 감사합니다