딥러닝, 머신러닝/논문리뷰
PoseAug
- -
https://paperswithcode.com/sota/weakly-supervised-3d-human-pose-estimation-on
Weakly supervised 3d human pose estimation SOTA
발표영상과 함께 보시면 좋을 것 같아 공유합니다.
https://www.youtube.com/watch?v=rfpw90_3IDQ
1. Introduction

기존 augmentation 방식 : 위의 이미지에서 보여지는 기존 연구들의 pose augmentation 방식은 이미지를 crop하거나 중간에 다른 object를 합성하는 방식을 사용하고 있습니다.
(하지만 이 케이스의 경우 2D pose를 3D pose로 lifting하는 거라 다른 방식의 사용이 가능하고, 이 논문에서는 network 기반 augmentation을 진행하고 있습니다.)
이 논문에서는 기존 augmentation 방식의 경우 데이터 증강과 모델 학습이 별도의 단계로 이뤄지기 때문에 모델 학습에 너무 쉬운 비효율적인 증강 데이터를 생성하는 경향이 있어 모델의 일반화 향상이 미미하다고 주장하고 있습니다.
그리고 정해진 데이터 안에서 하다보니 존재하는 학습 데이터 내에서의 관절 각도 제한이나 kinematics constraints(운동학적 제한)과 같은 미리 정의된 규칙에 의존해서 in-the-wild 이미지의 수준을 만들지 못합니다.
그래서 PoseAug는 네트워크 학습과 증강 프로세스를 공동으로 최적화하도록 한다.
augmentor는 3가지 유형의 증강 작업을 수행하는 방법을 학습합니다.
1) skeleton 관절 각도
2) 신체 크기
3) view point와 사람의 position
Contribution
1. 3D humon pose estimation에 대한 미분 가능한 data augmentation 최초의 연구
2. 다양하고 사실적인 2D-3D pose 쌍 생성, 일반화 능력 크게 향상시키는 error feedback 설계, differentiable(미분 가능한) pose augmentor
3. 포즈 영역을 나눠서 처리하기 때문에 augmented pose의 실현 가능한 영역이 확대되고, 데이터의 타당성과 다양성을 모두 보장할 수 있게 된다.
2. Related Work
1) 3D humon pose estimation : 일반화 능력을 향상시키기 위해 외부 정보를 활용하는 방법을 모색하고 있다. 정규화, in-the-wild 2D pose 데이터 활용, adversarial training[48, 44], geometry(기하학) 기반의 self-supervised learning[36, 10, ...]


2) Data augmentation on 3D human poses : 데이터의 타당성을 보장하기 위해 관절 각도 제한[1]을 하거나, 이미지 패치를 stitch하는 경우도 있고, 그래픽 엔진으로 새로운 데이터를 생성하기도 합니다.



3. PoseAug

x, X : real, x', X' : augmented data
(소문자 x는 2D, 대문자 X는 3D)
2D joint 데이터를 input으로 받고 3D joint로 lifting하는 task를 수행한다.
Pose Discriminator : 추론된 포즈가 맞는지를 판단하는 역할. augment된 포즈는 생체 역학 구조(bio-mechanical structure)를 위반하는 타당하지 않은 관절 각도 또는 불합리한 position 또는 view point를 나타낼 수 있다. 이러한 경우 증강된 포즈의 타당성 보장을 위해 증강을 안내하는 pose discriminator 모듈을 도입한다. 구체적으로 모듈은 관절 각도 타당성 평가를 위한 3D pose discriminator(D_3d), 신체 크기와 view point 및 position 타당성 평가를 위한 2D pose discriminator(D_2d)로 구성된다. part-aware KCS를 discriminator에 대한 입력으로 설계한다. part-aware KCS는 전신이 아닌 local pose angle에만 초점을 맞추므로 augmented pose의 실행 가능 영역을 확대해서 타당성과 다양성을 모두 보장한다.
X, X' 모두 bone directional Vector B~로 변환하고 그걸 5개의 파트로 나눈다.(torso, left/right arm/leg)

BA(Bone Angle) operation -> BL(Bone Length) operation -> RT(Rotation) operation

Pose Estimator : 2D pose에서 3D pose를 포즈를 추론하는 역할. 실험 전반에 걸쳐 달리 명시되지 않는 한 vpose의 single frame 버전을 포즈 추정기로 사용 (https://eehoeskrap.tistory.com/517, https://github.com/facebookresearch/VideoPose3D)
Pose Augmentor : 포즈 augmentation
offline 방식의 random pose augmentation 대신에, 제안된 pose augmentator A는 미분가능한 디자인을 취한다.
순수하게 오류를 최대화한 augmentation을 추구하면 인체의 생체역학적 구조를 위반하고 모델 성능을 손상시킬 수 있는 타당하지 않은 training pose data가 나올 수 있다. 이전의 증강 방법들은 타당성을 보장하기 위해 미리 정의된 규칙에 의존하지만 이는 생성된 포즈의 다양성을 심각하게 제한하게 된다. 그래서 신체 관절의 local relation에 pose discriminator를 배치해서 augmentor의 학습을 지원하고, 다양성을 희생하지 않으며, 증강된 포즈의 타당성을 보장한다.
Augmentor는 3D pose인 X가 주어지면, bone vector를 먼저 얻는다. bone vecotr는 한 joint와 인접한 joint의 연결이기 때문에 J-1개가 된다. 이 vector는 hierarchical transformation을 통해 bone direction vector(joint angle을 나타내는 vector)와 bone length vector(body size를 나타냄)로도 변환된다.
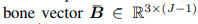
그리고 augmentor는 input 3D pose(X)에서 feature extraction을 위해 MLP를 사용한다. 여기에 추가적으로 가우시안 분포에 기반한 noise vector가 X에 concat시켜서 다양성을 증가시킨다. 추출된 features는 3개의 파라미터를 regress하기 위해 사용된다. 아래 이미지에서 순서대로 joint angles, body size, (View point, position)이다. Figure 3 참조.
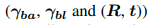
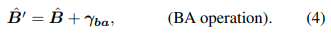

BL operation에서는 생체역학적 대칭을 보장하기 위해 left, right body parts는 같은 parameter를 공유하도록 한다.

R은 rotation을 나타내는 3x3 vector, t는 translation parameter이고, 각각 Rigid Transformation에서 pose view point와 position 처리에 필요한 파라미터이다. (같은 view point라도 위에서 보는거랑 아래서 보는 게 다르기 때문)
B'는 BA, BL operation에 의해 augment된 bone vector이다. H^-1 은 B'를 3D 포즈로 다시 변환하기 위한 inverse hierachical conversion이라고 보면된다.
이런 operation들을 적용함으로써 augmentor는 더 challenging한 pose와 body size, view point, position을 만들 수 있게 된다. 그리고 만들어진 3D pose에서 정한 카메라 시점에 따라 2D pose로 변환시켜서 3D pose, 2D pose 데이터를 둘다 만들게 된다.
Training Loss
- Pose estimation loss

GT인 X와 predicted pose X~를 MSE로 묶어서 처리했습니다. original pose와 augmented pose를 둘다 공동으로 사용해서 학습시켰습니다.
- Pose augmentation loss



augmented data는 original data보다 더 어렵게(L_p(X') > L_p(X)), 학습 프로세스에 안좋은 영향을 끼치지는 않도록(너무 어렵거나 다른 포즈를 만들지 않도록) B > 1로 하여 generated pose의 난이도를 control한다. (exp 함수 그래프에서 x값이 0일 때 1이기 때문에 1에서 빼도록 한 것 같다.)
학습이 진행되며 pose estimator는 점점 더 powerful해지기 때문에 B를 적절히 증가하도록 하여 더 challenging한 augmented data를 학습에 사용하도록 한다.
추가적으로 학습 과정에 문제가 될 수 있는 너무 어려운 케이스들을 막기 위해 rectified L2 loss를 augmentation parameter인 r_ba, r_bl을 regularizing하는 목적으로 사용한다. r은 r_ba, r_bl이고 r^-는 mean value이다. 앞의 두 식을 최종 조합해서 전체 augmentation loss L_a가 11번 식으로 나온다.
- Pose discrimination loss

LSGAN에서 사용하는 Least Square Loss를 사용한다.
(기존의 BCE Loss에 비해 좀 더 안정적인 학습이 가능하다고 한다.)
4. Results


기존의 모델들에 비해 PoseAug를 적용한 모델의 에러가 어느정도 줄은 걸 확인 할 수 있습니다.
5. Code

generator에서 사용하는 loss 중 adversarial loss입니다. GAN과 유사한 형식이라 real_loss는 generator에서 컨트롤이 불가능하지만 완전성을 위해 위와 같이 작성하는 것도 가능합니다. 실제로 generator는 fake_loss만 최소화하게 됩니다.
class PoseGenerator(nn.Module):
def __init__(self, args, input_size=16 * 3):
super(PoseGenerator, self).__init__()
self.BAprocess = BAGenerator(input_size=input_size)
self.BLprocess = BLGenerator(input_size=input_size, blr_tanhlimit=args.blr_tanhlimit)
self.RTprocess = RTGenerator(input_size=input_size)
def forward(self, inputs_3d):
'''
input: 3D pose
:param inputs_3d: nx16x3, with hip root
:return: nx16x3
'''
pose_ba, ba_diff = self.BAprocess(inputs_3d) # diff may be used for div loss
pose_bl, blr = self.BLprocess(inputs_3d, pose_ba) # blr used for debug
pose_rt, rt = self.RTprocess(inputs_3d, pose_bl) # rt=(r,t) used for debug
return {'pose_ba': pose_ba,
'ba_diff': ba_diff,
'pose_bl': pose_bl,
'blr': blr,
'pose_rt': pose_rt,
'rt': rt}
class BAGenerator(nn.Module):
def __init__(self, input_size, noise_channle=48, linear_size=256, num_stage=2, p_dropout=0.5):
super(BAGenerator, self).__init__()
self.linear_size = linear_size
self.p_dropout = p_dropout
self.num_stage = num_stage
self.noise_channle = noise_channle
# 3d joints
self.input_size = input_size # 16 * 3
# process input to linear size
self.w1 = nn.Linear(self.input_size + self.noise_channle, self.linear_size)
self.batch_norm1 = nn.BatchNorm1d(self.linear_size)
self.linear_stages = []
for l in range(num_stage):
self.linear_stages.append(Linear(self.linear_size))
self.linear_stages = nn.ModuleList(self.linear_stages)
# post processing
self.w2 = nn.Linear(self.linear_size, self.input_size - 3)
self.relu = nn.LeakyReLU(inplace=True)
def forward(self, inputs_3d):
'''
:param inputs_3d: nx16x3.
:return: nx16x3
'''
# convert 3d pose to root relative
root_origin = inputs_3d[:, :1, :] * 1.0
x = inputs_3d - inputs_3d[:, :1, :] # x: root relative
# extract length, unit bone vec
bones_unit = get_bone_unit_vecbypose3d(x)
bones_length = get_bone_lengthbypose3d(x)
# pre-processing
x = x.view(x.size(0), -1)
noise = torch.randn(x.shape[0], self.noise_channle, device=x.device)
y = self.w1(torch.cat((x, noise), dim=1))
y = self.batch_norm1(y)
y = self.relu(y)
# linear layers
for i in range(self.num_stage):
y = self.linear_stages[i](y)
y = self.w2(y)
y = y.view(x.size(0), -1, 3)
# modify the bone angle with length unchanged.
modifyed = bones_unit + y
modifyed_unit = modifyed / torch.norm(modifyed, dim=2, keepdim=True)
# fix bone segment from pelvis to thorax to avoid pure rotation of whole body without ba changes.
tmp_mask = torch.ones_like(bones_unit)
tmp_mask[:, [6, 7], :] = 0.
modifyed_unit = modifyed_unit * tmp_mask + bones_unit * (1 - tmp_mask)
cos_angle = torch.sum(modifyed_unit * bones_unit, dim=2)
ba_diff = 1 - cos_angle
modifyed_bone = modifyed_unit * bones_length
# convert bone vec back to 3D pose
out = get_pose3dbyBoneVec(modifyed_bone) + root_origin
return out, ba_diff
class RTGenerator(nn.Module):
def __init__(self, input_size, noise_channle=48, linear_size=256, num_stage=2, p_dropout=0.5):
super(RTGenerator, self).__init__()
'''
:param input_size: n x 16 x 3
:param output_size: R T 3 3 -> get new pose for pose 3d projection.
'''
self.linear_size = linear_size
self.p_dropout = p_dropout
self.num_stage = num_stage
self.noise_channle = noise_channle
# 3d joints
self.input_size = input_size # 16 * 3
# process input to linear size -> for R
self.w1_R = nn.Linear(self.input_size + self.noise_channle, self.linear_size)
self.batch_norm_R = nn.BatchNorm1d(self.linear_size)
self.linear_stages_R = []
for l in range(num_stage):
self.linear_stages_R.append(Linear(self.linear_size))
self.linear_stages_R = nn.ModuleList(self.linear_stages_R)
# process input to linear size -> for T
self.w1_T = nn.Linear(self.input_size + self.noise_channle, self.linear_size)
self.batch_norm_T = nn.BatchNorm1d(self.linear_size)
self.linear_stages_T = []
for l in range(num_stage):
self.linear_stages_T.append(Linear(self.linear_size))
self.linear_stages_T = nn.ModuleList(self.linear_stages_T)
# post processing
self.w2_R = nn.Linear(self.linear_size, 3)
self.w2_T = nn.Linear(self.linear_size, 3)
self.relu = nn.LeakyReLU(inplace=True)
# self.dropout = nn.Dropout(self.p_dropout)
def forward(self, inputs_3d, augx):
'''
:param inputs_3d: nx16x3
:return: nx16x3
'''
# convert 3d pose to root relative
root_origin = inputs_3d[:, :1, :] * 1.0
x = inputs_3d - inputs_3d[:, :1, :] # x: root relative
# pre-processing
x = x.view(x.size(0), -1)
# caculate R
noise = torch.randn(x.shape[0], self.noise_channle, device=x.device)
r = self.w1_R(torch.cat((x, noise), dim=1))
r = self.batch_norm_R(r)
r = self.relu(r)
# r = self.dropout(r)
for i in range(self.num_stage):
r = self.linear_stages_R[i](r)
r = self.w2_R(r)
r = nn.Tanh()(r) * 3.1415
r = r.view(x.size(0), 3)
rM = tgm.angle_axis_to_rotation_matrix(r)[..., :3, :3] # Nx4x4->Nx3x3 rotation matrix
# caculate T
noise = torch.randn(x.shape[0], self.noise_channle, device=x.device)
t = self.w1_T(torch.cat((x, noise), dim=1))
t = self.batch_norm_T(t)
t = self.relu(t)
for i in range(self.num_stage):
t = self.linear_stages_T[i](t)
t = self.w2_T(t)
t[:, 2] = t[:, 2].clone() * t[:, 2].clone()
t = t.view(x.size(0), 1, 3) # Nx1x3 translation t
# operat RT on original data - augx
augx = augx - augx[:, :1, :] # x: root relative
augx = augx.permute(0, 2, 1).contiguous()
augx_r = torch.matmul(rM, augx)
augx_r = augx_r.permute(0, 2, 1).contiguous()
augx_rt = augx_r + t
return augx_rt, (r, t) # return r t for debug
class BLGenerator(nn.Module):
def __init__(self, input_size, noise_channle=48, linear_size=256, num_stage=2, p_dropout=0.5, blr_tanhlimit=0.2):
super(BLGenerator, self).__init__()
'''
:param input_size: n x 16 x 3
:param output_size: R T 3 3 -> get new pose for pose 3d projection.
'''
self.linear_size = linear_size
self.p_dropout = p_dropout
self.num_stage = num_stage
self.noise_channle = noise_channle
self.blr_tanhlimit = blr_tanhlimit
# 3d joints
self.input_size = input_size + 15 # 16 * 3 + bl
# process input to linear size -> for R
self.w1_BL = nn.Linear(self.input_size + self.noise_channle, self.linear_size)
self.batch_norm_BL = nn.BatchNorm1d(self.linear_size)
self.linear_stages_BL = []
for l in range(num_stage):
self.linear_stages_BL.append(Linear(self.linear_size))
self.linear_stages_BL = nn.ModuleList(self.linear_stages_BL)
# post processing
self.w2_BL = nn.Linear(self.linear_size, 9)
self.relu = nn.LeakyReLU(inplace=True)
def forward(self, inputs_3d, augx):
'''
:param inputs_3d: nx16x3
:return: nx16x3
'''
# convert 3d pose to root relative
root_origin = inputs_3d[:, :1, :] * 1.0
x = inputs_3d - inputs_3d[:, :1, :] # x: root relative
# pre-processing
x = x.view(x.size(0), -1)
# caculate blr
bones_length_x = get_bone_lengthbypose3d(x.view(x.size(0), -1, 3)).squeeze(2) # 0907
noise = torch.randn(x.shape[0], self.noise_channle, device=x.device)
blr = self.w1_BL(torch.cat((x, bones_length_x, noise), dim=1))
blr = self.batch_norm_BL(blr)
blr = self.relu(blr)
for i in range(self.num_stage):
blr = self.linear_stages_BL[i](blr)
blr = self.w2_BL(blr)
# create a mask to filter out 8th blr to avoid ambiguity (tall person at far may have same 2D with short person at close point).
tmp_mask = torch.from_numpy(np.array([[1, 1, 1, 1, 0, 1, 1, 1, 1]]).astype('float32')).to(blr.device)
blr = blr * tmp_mask
# operate BL modification on original data
blr = nn.Tanh()(blr) * self.blr_tanhlimit # allow +-20% length change.
bones_length = get_bone_lengthbypose3d(augx)
augx_bl = blaugment9to15(augx, bones_length, blr.unsqueeze(2))
return augx_bl, blr # return blr for debug
def random_bl_aug(x):
'''
:param x: nx16x3
:return: nx16x3
'''
bl_15segs_templates_mdifyed = np.load('./data_extra/bone_length_npy/hm36s15678_bl_templates.npy')
# convert 3d pose to root relative
root = x[:, :1, :] * 1.0
x = x - x[:, :1, :]
# extract length, unit bone vec
bones_unit = get_bone_unit_vecbypose3d(x)
# prepare a bone length list for augmentation.
tmp_idx = np.random.choice(bl_15segs_templates_mdifyed.shape[0], x.shape[0])
bones_length = torch.from_numpy(bl_15segs_templates_mdifyed[tmp_idx].astype('float32')).unsqueeze(2)
modifyed_bone = bones_unit * bones_length.to(x.device)
# convert bone vec back to pose3d
out = get_pose3dbyBoneVec(modifyed_bone)
return out + root # return the pose with position information.class KCSpath(nn.Module):
def __init__(self, num_joints=16, channel=1000, channel_mid=100):
super(KCSpath, self).__init__()
# KCS path
self.kcs_layer_1 = nn.Linear(225, channel)
self.kcs_layer_2 = nn.Linear(channel, channel)
self.kcs_layer_3 = nn.Linear(channel, channel)
self.layer_last = nn.Linear(channel, channel_mid)
self.layer_pred = nn.Linear(channel_mid, 1)
self.relu = nn.LeakyReLU()
def forward(self, x):
# KCS path
psi_vec = self.relu(self.kcs_layer_1(x))
d1_psi = self.relu(self.kcs_layer_2(psi_vec))
d2_psi = self.kcs_layer_3(d1_psi) + psi_vec
y = self.relu(self.layer_last(d2_psi))
y = self.layer_pred(y)
return y
from utils.gan_utils import get_bone_unit_vecbypose3d, get_pose3dbyBoneVec, get_BoneVecbypose3d
class Pos3dDiscriminator(nn.Module):
def __init__(self, num_joints=16, kcs_channel=256, channel_mid=100):
super(Pos3dDiscriminator, self).__init__()
# only check on bone angle, not bone vector.
# KCS path
self.kcs_path_1 = KCSpath(channel=kcs_channel, channel_mid=channel_mid)
self.kcs_path_2 = KCSpath(channel=kcs_channel, channel_mid=channel_mid)
self.kcs_path_3 = KCSpath(channel=kcs_channel, channel_mid=channel_mid)
self.kcs_path_4 = KCSpath(channel=kcs_channel, channel_mid=channel_mid)
self.kcs_path_5 = KCSpath(channel=kcs_channel, channel_mid=channel_mid)
self.relu = nn.LeakyReLU()
def forward(self, inputs_3d):
# convert 3d pose to root relative
x = inputs_3d - inputs_3d[:, :1, :] # x: root relative
bv_unit = get_bone_unit_vecbypose3d(x)
x = get_pose3dbyBoneVec(bv_unit)
# KCS path
psi_vec_lh = kcs_layer_lh(x).view((x.size(0), -1))
k_lh = self.kcs_path_1(psi_vec_lh)
psi_vec_rh = kcs_layer_rh(x).view((x.size(0), -1))
k_rh = self.kcs_path_2(psi_vec_rh)
psi_vec_ll = kcs_layer_ll(x).view((x.size(0), -1))
k_ll = self.kcs_path_3(psi_vec_ll)
psi_vec_rl = kcs_layer_rl(x).view((x.size(0), -1))
k_rl = self.kcs_path_4(psi_vec_rl)
psi_vec_hb = kcs_layer_hb(x).view((x.size(0), -1))
k_hb = self.kcs_path_5(psi_vec_hb)
out = torch.cat([k_lh, k_rh, k_ll, k_rl, k_hb], dim=1)
return outclass Pos2dDiscriminator(nn.Module):
def __init__(self, num_joints=16):
super(Pos2dDiscriminator, self).__init__()
# Pose path
self.pose_layer_1 = nn.Linear(num_joints * 2, 100)
self.pose_layer_2 = nn.Linear(100, 100)
self.pose_layer_3 = nn.Linear(100, 100)
self.pose_layer_4 = nn.Linear(100, 100)
self.layer_last = nn.Linear(100, 100)
self.layer_pred = nn.Linear(100, 1)
self.relu = nn.LeakyReLU()
def forward(self, x):
# Pose path
x = x.contiguous().view(x.size(0), -1)
d1 = self.relu(self.pose_layer_1(x))
d2 = self.relu(self.pose_layer_2(d1))
d3 = self.relu(self.pose_layer_3(d2) + d1)
d4 = self.pose_layer_4(d3)
d_last = self.relu(self.layer_last(d4))
d_out = self.layer_pred(d_last)
return d_out참고자료
https://github.com/jfzhang95/PoseAug
https://arxiv.org/pdf/2105.02465.pdf
'딥러닝, 머신러닝 > 논문리뷰' 카테고리의 다른 글
| MeshGraphormer (0) | 2021.10.18 |
|---|---|
| Graph Attention Spatio-Temporal Convolutional Nets (GAST-Net) (0) | 2021.09.26 |
| FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning (0) | 2021.09.26 |
| End-to-End Human Pose and Mesh Reconstruction with Transformers (0) | 2021.09.04 |
| Monocular, One-stage, Regression of Multiple 3D People (0) | 2021.08.06 |
Contents
소중한 공감 감사합니다