딥러닝, 머신러닝/논문리뷰
End-to-End Human Pose and Mesh Reconstruction with Transformers
- -
microsoft에서 낸 transformer 기반의 mesh reconstruction 논문입니다.
https://www.youtube.com/watch?v=feCWifOxBi0
발표 영상을 같이 보시면 좋을 것 같아 공유드립니다.
1. Introduction
- SMPL과 같은 parametric 모델을 사용하고 그 모델의 paramter를 학습하는 모델 : 많이 사용되고, 좋은 성과가 나타나고 있지만, 결국 그 모델에 의존하기 때문에 Pose와 shape 표현이 어느 정도 제한되어 있다.
- parametric 모델을 사용하지 않는 경우 : graph convolution neural network을 이용해서 인접한 점들의 상호작용을 모델링하거나, 1D heatmap으로 vertex 좌표를 regress한다. 이러한 방식들은 인접해있지 않은 부분들의 vertex to vertex 상호작용을 모델링하는데 효율적이지 않다. 그래서 이 논문에서는 단거리 및 장거리(ex. 손과 발)를 포함하여 신체 관절과 mesh vertex 간의 상관관계를 학습하는 걸 목적으로 해서 transformer를 사용한다.
- 이 논문에서는 3D 신체 관절과 mesh vertices를 동시에 재구성하기 위해 transformer를 사용한다.
2. Related Works
- Human Mesh Reconstruction (HMR) : 기존 연구들에서는 SMPL, STAR, MANO와 같은 parametric 모델을 사용하고 그에 대한 parameter(pose, shape)를 학습하는 방법을 주로 하고 있다. input 이미지에서 pose, shape 파라미터를 직접 regress 하는 게 어렵기 때문에 최근 연구들에서는 2D joints, sementation maps과 같은 기타 정보들을 활용해서 학습을 진행하기도 한다. parametric 모델을 사용하지 않는 연구들 중 GraphCMR은 GCNN(graph convolutional neural network)를 사용해서 3D mesh vertices를 회귀하는 걸 목표로 한다. 최근 제안된 Pose2Mesh의 경우 GCNN을 사용한 cascaded 모델 구조를 취하고 있다. GCNN 기반의 방법은 인접한 vertex-vertex 상호 작용을 모델링하도록 설계되었지만, 장거리 상호 작용을 모델링하는데는 덜 효율적이다. 그래서 METRO에서는 제한 없이 관절과 mesh vertices 간의 global 상호 작용을 모델링한다.
- Attentions and Transformers : NLP 분야에서 많이 쓰이는 모델들로 BERT, GPT 등 Transformer 기반 모델들이 해당 분야에서 우수한 성능을 보이고 있다. 최근에는 image generation, classification에도 사용되고 있다.


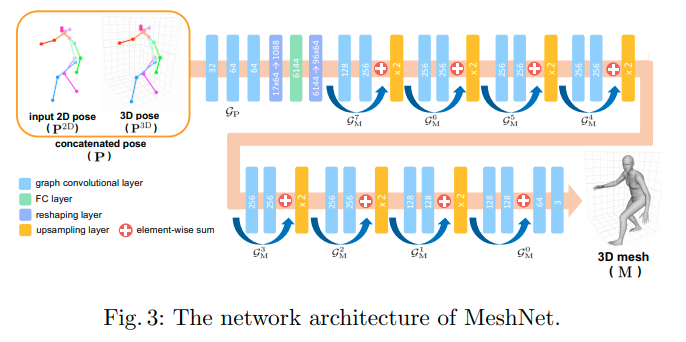

3. METRO

224x224 이미지를 input으로 사용하고, body joints J와 mesh vertices V를 예측한다. 먼저 CNN으로 input 이미지에서 image feature vector를 추출하고, Multi-Layer Transformer Encoder는 feature vector를 input으로 받아서 body joint와 mesh vertex를 병렬로 출력한다.
3.1. CNN
Image 분류 작업에 pretrained된 HRNet 모델을 사용하고, 마지막 hidden layer에서 dimension이 2048인 feature vector를 추출한다.
3.2. Multi-Layer Transformer Encoder with Progressive Dimensionality Reduction
Figure 2의 오른쪽 부분에서 볼 수 있듯이 multiple encoder layers를 만들어서 self-attention과 차원 축소를 같이 진행한다. 그래서 최종적으로 joints와 mesh vertices의 3D 좌표가 나오게 된다.
Figure 2의 왼쪽 부분에서 보면 transformer encoder의 input으로 body joint, mesh vertex query가 사용된다.




구체적으로 image feature vector인 X를 3D 좌표(x, y, z)와 concat을 하게 된다. 이 때의 x, y, z는 모든 body joint를 대상으로 한다. 이게 set of joint queries인 Q_J로 구성되고, 각각의 q_i_J는 2048 + 3인 2051차원으로 구성된다.
이와 유사하게 vertex query도 구성한다.


3.3. Masked Vertex Modeling
transformer encoder에서 bi-directional attention을 완전히 활성화하기 위해 회귀 작업을 위한 MVM(Masked Vertex Modeling)을 설계한다. 무작위로 입력 쿼리의 일부 비율을 마스킹한다. 누락된 쿼리에 해당하는 출력을 예측하기 위해 모델은 다른 관련 쿼리에 의존하게 되고, 이는 폐색을 시뮬레이션하는 경우와 비슷하다. 결과적으로 MVM은 거리 및 mesh topology에 관계 없이 다른 관련 vertices 및 joints를 고려하여 3D 좌표를 회귀하도록 transformer를 시행한다.
3.4. Training
학습 데이터로는 RGB 이미지 I와 3D vertices 데이터 V_3D, 3D joints 데이터 J_3D, 2D joints 데이터 J_2D를 사용한다.

L1 Loss를 사용해서 3D vetices와 3D joints의 predictions, ground truths를 최적화한다.
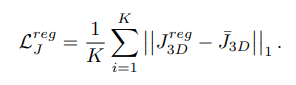
3D joints를 mesh vertices 데이터에서 추출하는 방법도 있기 때문에 pre-defined regression matrix를 활용해서 3D joints를 추론한 값과 ground truth를 L1 Loss로 사용한다.

2D re-projection도 많이 사용되고 있기 때문에 camera 파라미터를 이용해서 3D joints를 2D로 옮겨서 Loss로 만든다. (카메라 파라미터는 transformer encoder output의 상단에 있는 linear layer에서 학습해서 사용한다.)

3D 데이터 뿐만 아니라 2D 데이터만 있을 경우에도 사용할 수 있도록 하기 위해 binary flag(a, B)를 사용해서 최종 목적식을 작성한다.
4. Results


발표 시점 기준 Human3.6M, FreiHAND, 3DPW SOTA를 달성했다.

'딥러닝, 머신러닝 > 논문리뷰' 카테고리의 다른 글
| MeshGraphormer (0) | 2021.10.18 |
|---|---|
| Graph Attention Spatio-Temporal Convolutional Nets (GAST-Net) (0) | 2021.09.26 |
| FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning (0) | 2021.09.26 |
| PoseAug (0) | 2021.08.26 |
| Monocular, One-stage, Regression of Multiple 3D People (0) | 2021.08.06 |
Contents
소중한 공감 감사합니다